UDFをSQLに変換する仕組みを作ることで大幅に性能が改善したという研究の紹介
この記事はデータベース・システム系 Advent Calendar 2023の記事です。 今回はFroid: Optimization of Imperative Programs in a Relational Databaseという論文の内容を紹介します。データベースエンジンの詳細な実装を知らなくてもイメージがつかみやすい内容だと思うのでこういう研究もあるんだなーという気持ちで楽しく読んでいただけたらと思います。なお、この記事では要点のみをかいつまんで紹介しますので詳細が気になった方はぜひ論文の方をご参照ください。また、CMUの講義でも紹介されているのでこちらもご参照ください。
UDFとは
多くのRDBMSにはUDFやStored ProcedureなどのプログラミングをするようにDBへの処理を記述できる仕組みが存在します。以下は論文中でも紹介されているT-SQLというSQL Serverで用いられている言語で書かれたUDFの例です。
create function total_price(@key int) returns char(50) as begin declare @price float, @rate float; declare @pref_currency char(3); declare @default_currency char(3) = 'USD'; select @price = sum(o_totalprice) from orders where o_custkey = @key; select @pref_currency = currency from customer_prefs where custkey = @key; if(@pref_currency <> @default_currency) begin select @rate = xchg_rate(@default_currency,@pref_currency); set @price = @price * @rate; end return str(@price) + @pref_currency; end
変数にSELECT文の結果を代入してその後の分岐処理などに利用し、最後に結果をreturnするといったプログラミング言語らしい記述ができている事が分かるかと思います。また、UDFはSQLの中で利用する事が可能なので、例えば以下のように上で紹介したtotal_priceというUDFをクエリの中で呼び出す事も可能です。
select c_name, dbo.total_price(c_custkey) from customer;
このように、UDFには単一のSQLでサブクエリなどを使いこなして記述するよりも人にとって分かりやすい記述になったり、コンポーネントの再利用ができたりするなどのメリットがあります。
UDFの性能問題とその原因
ここまでに述べたようにUDFは便利な機能ではあるのですが、いくつかの理由から性能が十分に最適化されていませんでした。以下に論文中に記載されているSQL Serverの場合の原因を抜粋しましたが、一般にほかのDBMSでも当てはまるものとも記載されています。
- UDFを含むSQLの最適化についてUDFの処理内容が考慮されないのでオプティマイザーのコスト評価にUDFの内容がうまく反映されない
- UDFの処理系はSQLの処理系から関数を呼び出す形で実装されており、UDFの処理のたびに関数呼び出しが発生し、コンテキストスイッチのオーバーヘッドが発生する
- UDF内のクエリに対しては通常のクエリの場合に行うような並列処理がサポートされていない
- UDFの処理系はあくまで一行ずつ上から処理していくようなモデルであり、コンパイル言語で行われるような最適化が行われていない。
これらの背景には宣言的なパラダイムであるSQLの処理系と命令的なパラダイムであるUDFの処理系の間のインピーダンスミスマッチがあると著者らは述べています。そこでこの問題を解決するためにUDFの処理系とSQLの処理系を分けるのではなくUDFをSQLに変換*1してSQLの処理系で処理してしまおうというのが今回のアイデアです。
UDFをSQLに変換する
UDFの性能が最適化されていない部分についての理解があれば今回の論文のアイデア自体はとても単純で、「UDFをSQLの処理系で処理できるように変換して単一のSQLと見なせるようにすれば単一のSQLの処理系になるし、労力を割いて作ったオプティマイザーがいい感じに最適化してくれるはず」というものです。以下ではその実現方法と動作イメージを紹介します。
変換方法
ここでは一番のエッセンスにあたる、逐次処理をどのようにSQLに変換するかという部分について書きます。実際の代入処理や分岐命令などのSQLへのマッピングやその妥当性については論文に記載があるので興味のある方はそちらをご確認ください。
逐次処理の変換方法についてですが、これにはApply operator、一般にはlateral joinと呼ばれる操作を用います。lateral joinは左テーブルの結果を右テーブルの処理で利用する事ができるというものです。イメージとしてはUDFの各行をSQLのサブクエリに変換して、上から順に左から右に結合することで、UDFの上から順番に処理するイメージをSQLで表現できます。以下は論文中で紹介されている、最初に紹介したUDF、total_priceをApply operatorを用いて関係代数形式に変換したときのUDFの結合の図です。

なお、Apply operatorはもちろんオプティマイザーによる最適化の対象にあたるため、最終的に生成される実行計画はこのjoinの内容を理解した上でのコスト評価が行われ、UDFの処理系のように逐次実行ではなく諸々の最適化が行われ、必要に応じて並列処理なども行われる事が期待されます。
SQLに変換したUDFが最適化される様子
UDFがSQLに変換される事で最適化の際にUDFの中身が考慮されない問題や関数呼び出しのオーバーヘッド、並列処理のサポートの問題が一気に解決されることが期待できるのは想像できますが、UDFの処理系の最適化相当の事もオプティマイザーによって行われるという事が記載されています。

図中で上の段がUDFに対してコンパイルによる最適化が行われていた時の処理、下の段がSQLに変換したUDFに対してオプティマイザーが行う対応する最適化になります。まず、この処理では@xが1000より大きいかによって処理が分岐していますが、@xが与えられた段階でそうでない分岐の処理は削除できます。このような最適化(dynamic slicing)はオプティマイザーの前処理でも行われます。次に既に変数の値が分かっている演算を先に行うような最適化(constant propagation)もオプティマイザーが行います。また、参照されないパスの削除(dead code elimination)相当の処理も同様に行われます。
これらの最適化はUDFの処理系を改善するという形でも実現できるものではありますが、SQLに変換する事でこれらのメリットもいっしょについてくるというのはとても面白いところです。
改善結果
著者らはAzure SQL DatabaseにFroidのアイデアを実装し、実際のユーザーのワークロードでの改善度合いを評価しました。その中から特に目を引く図を一つ紹介します。

図よりサンプリングしたユーザーのUDFについてほぼすべてのUDFが性能改善し、そのほとんどが10倍以上、ものによっては 100倍程度の性能改善が確認できます。このような劇的な変化は通常なかなか見られないものだと思うので、このアイデアの強力さが感じられます。再帰が深い場合など変換をサポートできないUDFもあるようなので万能というわけではなさそうですが、すごい成果だと思いました。
まとめ
今回はFroidというUDFの性能改善の研究の紹介をしました。データベースの論文となると僕のようなデータベースユーザーにとっては普段あまり触らない内部のアルゴリズムなどの話題が多いですが、今回の内容はエンジンの詳細な実装には特に触れない内容で、親しみが湧くと同時に実はまだまだデータベースには課題がいろいろあるんだなと感じました。僕も研究者という職種ではないですが自分が関わる物事の中に何か一般的な課題が無いかであったり、それに対して汎用性のある解決策がないかという事は考えていきたいと思いました。以上です。
MySQLのcollationの動作を体系的に理解する
はじめに
collationとは二つの文字の間の順序を定義するものです。こう言われるととても単純に聞こえるのですが、MySQLのcollationの詳細な動作は実は結構複雑です。
この記事はcollationの挙動に関する体系的な解説と様々な具体例を元にcollationに対する理解を深め、collationの問題のトラブルシューティングの筋道を立てる事を目的としています。なお、この記事は大まかなcollationの動作の説明を目的としており、全てを網羅しているわけではありません。詳細な動作はMySQLの公式ドキュメントの方が丁寧ですので実際のトラブルシューティングではドキュメントもご活用ください。
なお、この記事での検証はMySQL8.0.31を利用しています。
collationの基礎
collationは冒頭で説明したように二つの文字の順序関係や同値関係を決めるものです。collationとセットで扱うものにcharacter setがありますが、character setが扱える文字を定義するとすれば、collationはcharacter setの文字をどの順序で並べるかを定義するものといえます。collationは一つもcharacter setに複数ある事があり、例えばアルファベットの大文字と小文字を区別するcollationと区別しないcollationや、ドイツ語などで用いられるウムラウト文字をアルファベット順でどこに置くかでいくつかのcollationがあったりします。
まずはイメージを掴むために実際に動作をさせてみます。
collationはクエリ中のあらゆる文字列データに対して設定されています。文字列のcollationはCOLLATION関数で確認できます。以下の一つ目の例では'test'という文字列のcollation、二つ目の例ではuserテーブルのレコードを取得してそのnameカラムの値のcollationを確認しています。
mysql> select collation('test'); +--------------------+ | collation('test') | +--------------------+ | utf8mb4_0900_ai_ci | +--------------------+ mysql> select collation(name) from user limit 1; +--------------------+ | collation(name) | +--------------------+ | utf8mb4_0900_ai_ci | +--------------------+
あまりやらないと思いますが文字列のcollationを明示的に指定する事もできます。以下の例では'test'という文字列にutf8mb4_general_ciを明示的に指定しています。
mysql> select collation('test' collate utf8mb4_general_ci); +-----------------------------------------------+ | collation('test' collate utf8mb4_general_ci) | +-----------------------------------------------+ | utf8mb4_general_ci | +-----------------------------------------------+
collationによって一致関係や順序関係は変化します。以下の一つ目はアルファベットの大文字と小文字を区別しないutf8mb4_0900_ai_ciの場合の'A'と'a'の等号関係が成り立ちますが、大文字と小文字を区別するutf8mb4_0900_as_csでは等号関係が成り立たない事がわかります。
mysql> select 'A' collate utf8mb4_0900_ai_ci = 'a' collate utf8mb4_0900_ai_ci; +-----------------------------------------------------------------+ | 'A' collate utf8mb4_0900_ai_ci = 'a' collate utf8mb4_0900_ai_ci | +-----------------------------------------------------------------+ | 1 | +-----------------------------------------------------------------+ 1 row in set (0.00 sec) mysql> select 'A' collate utf8mb4_0900_as_cs = 'a' collate utf8mb4_0900_as_cs; +-----------------------------------------------------------------+ | 'A' collate utf8mb4_0900_as_cs = 'a' collate utf8mb4_0900_as_cs | +-----------------------------------------------------------------+ | 0 | +-----------------------------------------------------------------+ 1 row in set (0.00 sec)
二つの文字列が異なるcollationの場合、それらを比較しようとするとどうなるでしょうか?一般的な感覚だと順序付けが異なる文字列の比較はできないのでエラーが発生すると思います。実際文字列に異なるcollationを設定して比較しようとした以下のケースではIllegal mix of collationsというエラーが発生します。
mysql> select 'A' collate utf8mb4_0900_as_cs = 'a' collate utf8mb4_0900_ai_ci; ERROR 1267 (HY000): Illegal mix of collations (utf8mb4_0900_as_cs,EXPLICIT) and (utf8mb4_0900_ai_ci,EXPLICIT) for operation '='
ですが、このあと見ていくように実際にはcollationが異なる文字列を比較してもエラーが発生せずに動作する事がほとんどで、中にはエラーは発生しないがインデックスはちゃんと使ってくれないといった厄介なケースもあります。この記事ではなぜこういった挙動が発生するのかを理解できるようになる事を目指します。
この記事で行うcollationの動作の解説の概要
以下ではcollationの詳細な動作の解説を行っていきますが、ここでは先に全体像の説明を行います。
MySQLのドキュメントや実際の挙動の理解を進める中で、collationの挙動は大まかには以下の二つのステップに分ける事で分かりやすくなると考えました。
- 各文字列のcollationを決定する
- collationが異なる文字列同士の比較が行われた場合の挙動の決定方法
collationのトラブルはだいたいcollationが異なる文字列を比較した時に発生するので、そもそも各文字列のcollationがどのように決まるかを理解し、その上で異なる場合にどのようなロジックで挙動が決まるかを理解すれば良いというのは自然な分け方だと思います。
その上で各ステップについて以下のトピックが複雑かつ重要であると感じました。
各文字列のcollationを決定する上では以下のトピック
- 文字列の定義のされ方によりcollationがどのように決まるかのロジック
- 特にカラム定義のcollationがどのように決まるかのロジック
collationが異なる文字列同士の比較が行われた場合の挙動を決定する上では以下のトピック
- 文字列の定義のされ方によるcollationの強制性
- collation間の包含関係
この記事ではこれらの各トピックに関する解説を実例を交えながら行っていきます。
各文字列のcollationを決定する
まずはクエリ中に発生する文字列のcollationの決定方法について説明します。先ほど説明したようにここでは特に複雑で重要な「文字列の定義のされ方でcollationがどのように決まるか」と「特にカラム定義のcollationがどのように決まるか」の二つを解説します。
文字列の定義のされ方によりcollationがどのように決まるかのロジック
文字列には様々な定義の仕方があります。ここではよく使われる文字列の定義の仕方でどのようにcollationが定まるかを見ていきます。
文字列リテラル
ユーザーがクエリを実行する時に渡すような文字列リテラルのcollationはcollation_connectionで決まります。以下では'test'が文字列リテラルで、collation_connectionのセッション変数を変更する事で'test'のcollationが変化する事が確認できます。
mysql> select collation('test'); +--------------------+ | collation('test') | +--------------------+ | utf8mb4_0900_ai_ci | +--------------------+ 1 row in set (0.00 sec) mysql> set local collation_connection=utf8mb4_general_ci; Query OK, 0 rows affected (0.00 sec) mysql> select collation('test'); +--------------------+ | collation('test') | +--------------------+ | utf8mb4_general_ci | +--------------------+ 1 row in set (0.01 sec)
例えばselect * from sample where name='hoge';の'hoge'も同じく文字列リテラルなのでcollation_connectionで決まります。
カラムの文字列
カラムの文字列のcollationの決まり方については後述しますが、確認方法としてはshow create tableを実行してカラムに対して明示的にcollationが指定されていればその値、そうでなければテーブルに紐づくcollationが使われます。
以下ではテーブルのcollationにutf8mb4_0900_ai_ciを設定している場合に、collationを指定していないvarcharカラムのnameではutf8mb4_0900_ai_ciが利用され、明示的にcollationにutf8mb4_general_ciを指定している場合にはutf8mb4_general_ciが利用されている事がわかります。
mysql> show create table sample; +--------+--------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+ | Table | Create Table | +--------+--------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+ | sample | CREATE TABLE `sample` ( `id` int DEFAULT NULL, `name` varchar(10) DEFAULT NULL, `name2` varchar(10) CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci DEFAULT NULL ) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_0900_ai_ci | +--------+--------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+ 1 row in set (0.01 sec) mysql> select collation(name), collation(name2) from sample; +--------------------+--------------------+ | collation(name) | collation(name2) | +--------------------+--------------------+ | utf8mb4_0900_ai_ci | utf8mb4_general_ci | +--------------------+--------------------+
stored procedureの中の値
stored procedureやstored functionの引数や宣言した変数の文字列型のデータや文字列リテラルにもcollationがあります。これらについてはstored procedureに紐づくcollation_connection、引数はstored procedureに紐づくDATABASE_COLLATIONで決まります。
以下では引数(input)、文字列のローカル変数(a)、ユーザー定義変数@b、文字列データそのもののそれぞれのcollationを確認しています。
mysql> select routine_name, routine_definition, collation_connection, database_collation from information_schema.routines where routine_name='test'\G; *************************** 1. row *************************** ROUTINE_NAME: test ROUTINE_DEFINITION: begin declare a varchar(10); set a='a'; set @b='a'; select collation(input), collation(a), collation(@b), collation('a'); end COLLATION_CONNECTION: utf8mb4_general_ci DATABASE_COLLATION: utf8mb4_0900_ai_ci mysql> call test('a'); +--------------------+--------------------+--------------------+--------------------+ | collation(input) | collation(a) | collation(@b) | collation('a') | +--------------------+--------------------+--------------------+--------------------+ | utf8mb4_0900_ai_ci | utf8mb4_0900_ai_ci | utf8mb4_general_ci | utf8mb4_general_ci | +--------------------+--------------------+--------------------+--------------------+ 1 row in set (0.00 sec) Query OK, 0 rows affected (0.01 sec)
この結果から以下の挙動が分かります。
- 引数や内部で宣言された変数のcollationはstored procedureに紐づくDATABASE_COLLATIONで決まる
- stored procedure中の文字列リテラルはstored procedureに紐づくCOLLATION_CONNECTIONで決まる
- @で変数を宣言するユーザー定義変数では引数の文字列のcollationが引き継がれるため今回は文字列リテラルと同じCOLLATION_CONNECTIONの値が使われた。これはおそらくユーザー定義変数の動作によるものです。
なお、COLLATION_CONNECTIONやDATABASE_COLLATIONはstored procedureに紐づくものなので例えばset local collation_connection=utf8mb4_0900_ai_ciなどとした状態でこのstored procedureを実行しても実行結果は変化しません。
明示的なcollationの指定
冒頭に述べたようにCOLLATE句を用いて明示的にcollationを設定する事が可能で、この場合は明示的な設定が優先されます。 また、以下のようにソート順で明示的にcollationを設定することもできます。
select name from sample order by name collate utf8mb4_general_ci;
カラムのcollationがどのように決まるかのロジック
カラムのcollationはcreate tableやadd columnを実行する際にcollationを渡すというわかりやすいやり方もありますが、特に指定しなくても自動でcollationが設定されます。ここではその挙動の解説を行います。分量は多いですが大半は自然に連想できる動作だと思いますので流し読みで大丈夫だと思います。また、大体ドキュメントに書いてある内容です。
まず、MySQLはサーバー、データベース、テーブル、カラムの各レイヤーでcharacter setとcollationの設定を持っています。以下ではそれぞれの場合のcharacter setとcollationの決まり方を見ていきます。
サーバーレベルでのcharacter setとcollation
character_set_serverおよびcollation_serverというシステム変数で設定されています。
データベースレベルでのcharacter setとcollation
データベースレベルでのcharacter setとcollationは以下のように決まります。
- create database時にcharacter setとcollationを両方指定している場合は指定した値が使われます。
- collationのみ設定している場合はそのcollationと関連するcharacter setが使われます。
- character setのみが設定されている場合、そのcharacter setのdefault collationが使われます。
- どちらも設定していない場合サーバーレベルのcharacter setとcollationが使われます。
character setのみが設定されている場合以外は自然だと思うので、この場合について補足をします。
まず、default collationとはMySQLが事前に決めている各character setのデフォルトのcollationで、これは以下のようにshow character setで確認できます。
mysql> show character set like 'utf8mb4'; +---------+---------------+--------------------+--------+ | Charset | Description | Default collation | Maxlen | +---------+---------------+--------------------+--------+ | utf8mb4 | UTF-8 Unicode | utf8mb4_0900_ai_ci | 4 | +---------+---------------+--------------------+--------+
もしcreate databaseを実行する際にcharacter setのみを指定する場合はこのdefault collationが利用されるという事に注意してください。特に、character_set_serverと同じ文字セットであっても明示的に文字セットを指定するとcollation_serverの値ではなくdefault collationが使われるという点に注意です。
以下の例ではcollation_serverにutf8mb4_general_ciを指定した時にcharacter setもcollationも設定しなかったutf8mb4_1ではcollationがcollation_serverと同じになり、character setをutf8mb4に設定しつつcollationは設定しなかったデータベース、utf8mb4_2ではdefault collationであるutf8mb4_0900_ai_ciが用いられている事がわかります。
mysql> show variables like 'collation_server'; +------------------+--------------------+ | Variable_name | Value | +------------------+--------------------+ | collation_server | utf8mb4_general_ci | +------------------+--------------------+ 1 row in set (0.01 sec) mysql> show create database utf8mb4_1; +-----------+-------------------------------------------------------------------------------------------------------------------------------------+ | Database | Create Database | +-----------+-------------------------------------------------------------------------------------------------------------------------------------+ | utf8mb4_1 | CREATE DATABASE `utf8mb4_1` /*!40100 DEFAULT CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci */ /*!80016 DEFAULT ENCRYPTION='N' */ | +-----------+-------------------------------------------------------------------------------------------------------------------------------------+ 1 row in set (0.00 sec) mysql> create database utf8mb4_2 character set utf8mb4; Query OK, 1 row affected (0.07 sec) mysql> show create database utf8mb4_2; +-----------+-------------------------------------------------------------------------------------------------------------------------------------+ | Database | Create Database | +-----------+-------------------------------------------------------------------------------------------------------------------------------------+ | utf8mb4_2 | CREATE DATABASE `utf8mb4_2` /*!40100 DEFAULT CHARACTER SET utf8mb4 COLLATE utf8mb4_0900_ai_ci */ /*!80016 DEFAULT ENCRYPTION='N' */ | +-----------+-------------------------------------------------------------------------------------------------------------------------------------+
この挙動はテーブルやカラムでも同様の挙動なので気をつけてください。
なお、default collationの設定は基本的にユーザーの方で変更する事ができませんが、utf8mb4に限りdefault_collation_for_utf8mb4でutf8mb4_general_ciかutf8mb4_0900_ai_ciに限り選択を行う事ができます。ただし、これは後方互換性のため一時的な措置のようで、実際に以下のように設定してみるとわかるようにdeplication warningが発生します。
mysql> set global default_collation_for_utf8mb4 ='utf8mb4_general_ci'; Query OK, 0 rows affected, 1 warning (0.00 sec) mysql> show warnings; +---------+------+--------------------------------------------------------------------------------------------------------+ | Level | Code | Message | +---------+------+--------------------------------------------------------------------------------------------------------+ | Warning | 1681 | Updating 'default_collation_for_utf8mb4' is deprecated. It will be made read-only in a future release. | +---------+------+--------------------------------------------------------------------------------------------------------+
テーブルレベルのcharacter setとcollation
大体データベースと同様になります。
- character setとcollationを両方指定している場合は指定した値が使われます。
- collationのみ設定している場合はそのcollationと関連するcharacter setが使われます。
- character setのみが設定されている場合、そのcharacter setのdefault collationが使われます。
- どちらも設定していない場合データベースレベルのcharacter setとcollationが使われます。
カラムレベルのcharacter setとcollation
データベースレベルとテーブルレベルの挙動を理解していたら大体同じようにわかると思います。
- character setとcollationを両方指定している場合は指定した値が使われます。
- collationのみ設定している場合はそのcollationと関連するcharacter setが使われます。
- character setのみが設定されている場合、そのcharacter setのdefault collationが使われます。
- どちらも設定していない場合テーブルレベルのcharacter setとcollationが使われます。
collation_databaseの役割
本筋から少し離れますが、collationに関するvariablesを確認するとまだ出てきていない変数、collation_databaseというものがあります。
mysql> show variables like '%collation_%'; +-------------------------------+--------------------+ | Variable_name | Value | +-------------------------------+--------------------+ | collation_connection | utf8mb4_0900_ai_ci | | collation_database | utf8mb4_0900_ai_ci | | collation_server | utf8mb4_0900_ai_ci | | default_collation_for_utf8mb4 | utf8mb4_0900_ai_ci | +-------------------------------+--------------------+
これは何をやっているかというと、現在のデータベース(use ...で指定したデータベース)のcollationを表示してくれるものになります。この変数はユーザーが設定するものではないのでご注意ください。
collationの定義のされ方まとめ
おおまかにはユーザーが渡した文字列はcollation_connectionで決まる事、カラムのデータはカラム定義でcollationが決まっているという事と、カラム定義のcollationはcharacter set含めて特に指定しなければサーバー、データベース、テーブル、カラムの各設定が引き継がれているという事を理解すれば大丈夫だと思います。
collationが異なる文字列同士の比較が行われた場合の挙動の決定方法
ここまでで各文字列のcollationがどのように決まるかが分かったと思うので、ここからでは実際のクエリに複数のcollationが存在する場合の動作を説明します。ここで重要な概念は「collationの強制性」と「collationの包含関係」の二つです。以下でそれぞれについて説明していきます。
collationの強制性
以下の例はcollation_connectionがutf8mb4_general_ciとなっている状況でcollationがutf8mb4_0900_ai_ciのnameカラムと文字列リテラルを比較して検索をする例です。異なるcollationの比較になりますがどういった動作になるでしょうか?
mysql> show variables like 'collation_connection'; +----------------------+--------------------+ | Variable_name | Value | +----------------------+--------------------+ | collation_connection | utf8mb4_general_ci | +----------------------+--------------------+ 1 row in set (0.03 sec) mysql> show create table test; +-------+----------------------------------------------------------------------------------------------------------------------------+ | Table | Create Table | +-------+----------------------------------------------------------------------------------------------------------------------------+ | test | CREATE TABLE `test` ( `name` varchar(10) DEFAULT NULL ) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_0900_ai_ci | +-------+----------------------------------------------------------------------------------------------------------------------------+ 1 row in set (0.01 sec) mysql> select * from test where name='a';
'a'はcollation_connectionで決まるのでutf8mb4_general_ci、対象のカラムはutf8mb4_0900_ai_ciと異なるのでエラーが発生すると思いたいところですが、実はクエリは実行可能です。
これは各文字列の定義のされ方によってcollationが決まるだけでなく強制性というものも設定され、異なるcollationの文字列の比較が行われる場合は強制性がより0に近い文字列のcollationを使う挙動になっているためです。
なお、各文字列のcollationの強制性はCOERCIBILITY関数で確認できます。
強制性はどのように定まるのか
強制性はその文字列の定義のされ方によって定まります。「文字列の定義のされ方によりcollationがどのように決まるかのロジック」で説明した各場合については以下のように強制性が設定されています。0の優先度が一番高く、1, 2, 3…と優先度が低くなります。
- 文字列リテラルは4
- カラムの文字列は2
- stored procedureの引数や変数は2
- 明示的にcollationの定義をした場合は0
先程の例では文字列リテラルの強制性が4でカラムの文字列の強制性が2なのでカラムの文字列のcollation、つまりutf8mb4_0900_ai_ciに合わせてクエリが実行されたことになります。では次のように検索に用いる文字列リテラルのcollationを明示的に指定するとどうなるでしょうか。
select * from test where name='a' collate utf8mb4_general_ci;
この場合'a'の強制性は0になるのでutf8mb4_general_ciに合わせて実行されます。 以下のように大文字小文字を区別するcollationとそうでないcollationで結果の変化を見るとわかりやすいと思います。
mysql> select * from test where name='a'; +------+ | name | +------+ | a | | A | +------+ 2 rows in set (0.00 sec) mysql> select * from test where name='a' collate utf8mb4_0900_as_cs; +------+ | name | +------+ | a | +------+ 1 row in set (0.00 sec)
異なるcollationを用いられた時にインデックスが使えない事がある
先ほどの最後の例のように、MySQLはcollationが異なる場合も強制性が異なる場合は強制性が0に近い方に合わせる動作をする事でエラーを返さずに実行が可能になります。しかし、文字列データをキーとするインデックスはその文字列のcollation順になっているので、異なるcollationで検索をされるとうまくインデックスが使えない場合があります。
以下の例ではutf8mb4_0900_ai_ciをnameカラムに用いており、かつnameカラムのインデックスを持つテーブルについて、検索に用いる文字列リテラルのcollationを指定しない場合と明示的にnameカラムと異なるcollationを指定した場合のexplainの結果を確認しています。検索時に明示的に文字列リテラルのcollationにカラムと異なるcollationを設定する後者ではインデックスが効かなくなりフルインデックススキャンしています。
mysql> explain select * from test where name='a'; +--+-----------+-----+----------+----+-------------+----+-------+-----+----+--------+-----------+ | id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra | +--+-----------+-----+----------+----+-------------+----+-------+-----+----+--------+-----------+ | 1 | SIMPLE | test | NULL | ref | name | name | 43 | const | 1 | 100.00 | Using index | +--+-----------+-----+----------+----+-------------+----+-------+-----+----+--------+-----------+ 1 row in set, 1 warning (0.00 sec) mysql> explain select * from test where name='a' collate utf8mb4_general_ci; +--+-----------+-----+----------+-----+-------------+----+-------+----+----+--------+------------------------+ | id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra | +--+-----------+-----+----------+-----+-------------+----+-------+----+----+--------+------------------------+ | 1 | SIMPLE | test | NULL | index | name | name | 43 | NULL | 4 | 25.00 | Using where; Using index | +--+-----------+-----+----------+-----+-------------+----+-------+----+----+--------+------------------------+ 1 row in set, 3 warnings (0.00 sec)
強制性が同じ場合の動作
ここまでで文字列のcollationの強制性が異なる場合はエラーを発生せずに強制性が0に近い方に合わせる事がわかりました。ですが、しばしば強制性が同じケースがあります。一番分かりやすいのはcollationの異なるカラムのjoinで、どちらもカラムに格納されたデータなのでcollationの強制性は2です。以下ではtestテーブルのnameカラムはutf8mb4_0900_ai_ci、test2テーブルのnameカラムはutf8mb4_general_ciとなっており、これらのカラムでjoinします。
mysql> show create table test; +-------+----------------------------------------------------------------------------------------------------------------------------+ | Table | Create Table | +-------+----------------------------------------------------------------------------------------------------------------------------+ | test | CREATE TABLE `test` ( `name` varchar(10) DEFAULT NULL ) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_0900_ai_ci | +-------+----------------------------------------------------------------------------------------------------------------------------+ 1 row in set (0.01 sec) mysql> show create table test2; +-------+--------------------------------------------------------------------------------------------------------------------------------------------------------+ | Table | Create Table | +-------+--------------------------------------------------------------------------------------------------------------------------------------------------------+ | test2 | CREATE TABLE `test2` ( `name` varchar(10) COLLATE utf8mb4_general_ci DEFAULT NULL ) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_general_ci | +-------+--------------------------------------------------------------------------------------------------------------------------------------------------------+ 1 row in set (0.01 sec) mysql> select test.name from test join test2 on test.name=test2.name; ERROR 1267 (HY000): Illegal mix of collations (utf8mb4_0900_ai_ci,IMPLICIT) and (utf8mb4_general_ci,IMPLICIT) for operation '='
Illegal mix of collationsのエラーが発生しました。このように基本的には強制性が同一かつcollationが異なる場合、エラーを発生します。以下の例も同様にエラーを発生します。
mysql> select 'A' collate utf8mb4_0900_as_cs = 'a' collate utf8mb4_0900_ai_ci; ERROR 1267 (HY000): Illegal mix of collations (utf8mb4_0900_as_cs,EXPLICIT) and (utf8mb4_0900_ai_ci,EXPLICIT) for operation '='
この場合は両方とも強制性が0ですね。このように、強制性が同じ場合は通常エラーを発生します。ですが、この動作には実は例外があります。次に最後のトピック、collation間の包含関係の解説をします。
collation間の包含関係
以下はcollationの異なるカラムをjoinする例です。ここではtestテーブルのnameカラムはutf8mb4_0900_ai_ci、test3テーブルのnameカラムはutf8mb4_binです。このクエリは少し上の例ではエラーが発生しましたが、今回はなぜかエラーが発生しません。
mysql> show create table test; +-------+----------------------------------------------------------------------------------------------------------------------------+ | Table | Create Table | +-------+----------------------------------------------------------------------------------------------------------------------------+ | test | CREATE TABLE `test` ( `name` varchar(10) DEFAULT NULL ) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_0900_ai_ci | +-------+----------------------------------------------------------------------------------------------------------------------------+ 1 row in set (0.01 sec) mysql> show create table test3; +-------+------------------------------------------------------------------------------------------------------------------------------------------+ | Table | Create Table | +-------+------------------------------------------------------------------------------------------------------------------------------------------+ | test3 | CREATE TABLE `test3` ( `name` varchar(10) COLLATE utf8mb4_bin DEFAULT NULL ) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_bin | +-------+------------------------------------------------------------------------------------------------------------------------------------------+ 1 row in set (0.00 sec) mysql> select test.name from test join test3 on test.name=test3.name; Empty set (0.00 sec)
なぜこれはエラーが起きないのでしょうか?
実はutf8mb4_binはutf8mb4_0900_ai_ciのスーパーセットになっています。このような場合、utf8mb4_binを用いて比較が可能になります。一方でutf8mb4_general_ciとuf8_mb4_0900_ai_ciの例では二つの間に包含関係が無いためにエラーになりました。
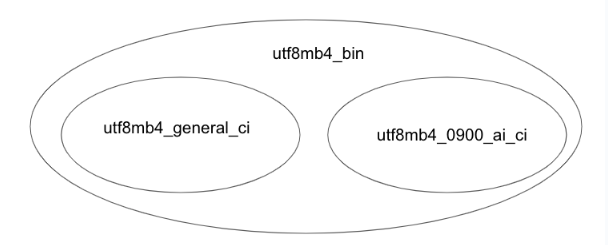
この動作の正当性の説明をするとutf8mb4_binはバイナリ順序での比較なのでcollationがutf8mb4_ai_ciの文字列もバイナリ順序で比較ができるのでutf8mb4_binに寄せて実行できるから実行したという事なのですが、大事なのはこのようにcollation間に包含関係がある場合、スーパーセットに寄せて比較が行われるという事です。また、この場合はutf8mb4_binでない方のテーブルは文字列リテラルにカラムと異なるcollationを指定した場合の例と同様に実際のインデックスと異なる照合順序で比較する事になるのでインデックスが使えない可能性が高い点には気をつけてください。
最後に、これは補足ですがcollationを明示的に指定している場合は包含関係があってもエラーになるようです。以下では両方とも強制性が0で包含関係がありますが、明示的にcollationを指定しているのでエラーになります。エラーメッセージにEXPLICITの文字があります。
mysql> select 'A' collate utf8mb4_bin = 'a' collate utf8mb4_0900_ai_ci; ERROR 1267 (HY000): Illegal mix of collations (utf8mb4_bin,EXPLICIT) and (utf8mb4_0900_ai_ci,EXPLICIT) for operation '='
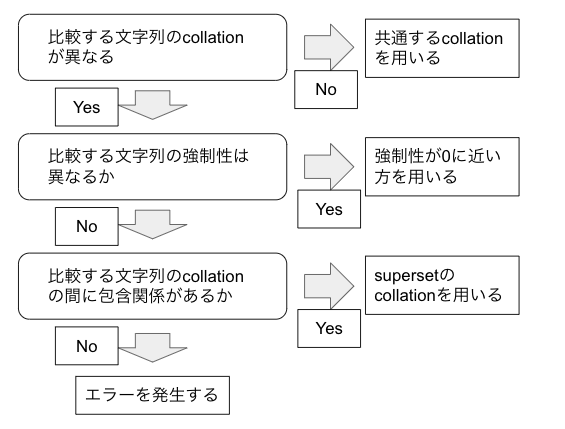
collationが異なる文字列同士の比較が行われた場合の挙動の決定方法のまとめ
collationが異なる文字列同士の比較時の挙動をまとめると基本的には以下のフロー図になります。
最後に
この記事では複雑でとっつきにくいMySQLのcollationの動作の体系的な解説を目指しました。
要点としては各文字列データのcollationが何かを確認し、異なるcollationの比較が発生した時はここで紹介したフローチャートに従ってどのような動作をするか考えるという感じです。複雑で大変だと思いますが何かcollation関連のトラブルにあったら参考にしてもらえたら幸いです。
MySQLエラー調査: Table definition has changed, please retry transaction
はじめに
こんにちは、![]() id:shallow1729です。小ネタですが、先日”ERROR 1412 (HY000): Table definition has changed, please retry transaction”というエラーに出会ったのでそれの調査をします。MySQL8.0.31をベースにします。
id:shallow1729です。小ネタですが、先日”ERROR 1412 (HY000): Table definition has changed, please retry transaction”というエラーに出会ったのでそれの調査をします。MySQL8.0.31をベースにします。
エラーの意味
まずエラーメッセージで調べると以下の公式ドキュメントが出てきました。
https://dev.mysql.com/doc/refman/8.0/en/innodb-consistent-read.html
Consistent read does not work over ALTER TABLE operations that make a temporary copy of the original table and delete the original table when the temporary copy is built. When you reissue a consistent read within a transaction, rows in the new table are not visible because those rows did not exist when the transaction's snapshot was taken. In this case, the transaction returns an error: ER_TABLE_DEF_CHANGED, “Table definition has changed, please retry transaction”.
まずconsistent readですが、ここではMVCCを使っている場合の話をしています。MVCCの詳細は過去に書いたことあるのでそちらを参照いただけたらと思います*1が、ざっくりとはデータの変更があった場合は変更前のバージョンのログを残しておき、各トランザクションに開始時のタイムスタンプを持たせる事で自身の開始時のバージョンを見に行くようにする仕組みです。MySQLのデフォルトのREPEATABLE READだとトランザクション開始後に読んだデータを他のトランザクションによって変更がコミットされた後にもう一度読みに行っても一回目に読んだ時と同じ結果を見れる(一貫性のある読み取りができる)のですが、これはMVCCの仕組みのおかげです。
なのですが、DDLについてはMVCCでのバージョン管理の外で行われるのでALTER TABLEしてしまうと過去のバージョンを参照できないのでconsistent readを提供できないからエラーにするという挙動のようです。もう一回実行すれば大丈夫だよというのもまあそうって感じですね。
ちなみにドキュメントの説明はかなりALGORYTHM=COPYっぽい感じですがALGORYTHM=INSTANTでも再現できます。
再現方法
session1: BEGIN; session1: SELECT * FROM NOT_TARGET_TABLE; session2: ALTER TABLE TARGET_TABLE ADD hoge int; session1: SELECT * FROM TARGET_TABLE;
SELECT * FROM NOT_TARGET_TABLE;を入れてるのはデフォルトではMySQLのMVCCのタイムスタンプの払い出しのタイミングが一つ目のクエリのタイミングだからです。
詳細な動作の調査
とりあえずドキュメントのおかげでエラーを吐かせたモチベーションは理解できたのですが、本番環境で無停止でDDLオペレーションをする時にこのエラーによりリクエストが失敗するのはどの程度起こるかなどの見積もりは欲しいので、そういった事を考えるために詳細な発生条件を考えます。
このエラーが発生した時クエリはテーブルにアクセスはできるのか
実際にはこのエラーは一分程度まばらに発生したのですが、この時に気になったのが、これは一分間そのテーブルへのアクセスができない状態だったのか、そうでない一部なのかという点でした。
テーブルにアクセスできない可能性が気になったのは、メタデータロックというMySQLのDDLで気を遣わないといけないことがよく知られた事があるからです。メタデータロックはテーブル定義に対して取るロックで、そのテーブルのレコードの読み書きやDDLが行われる時にそのトランザクションで取得されます。そして、このトランザクションは、トランザクションの終了時(commit/rollback時)に解放されます。基本的にレコードの読み書きの際はテーブル定義は参照のみなのでshared lockで構わないのですが、DDLはテーブル定義の書き込みなのでexclusive lockでないといけません。で、このロックの取得のやり方が、ナイーブに現状取られているshared lockを全部待って、exclusive lockを取るスレッドの後のshared lockを取りたいスレッドを全部待たせるという仕組みなので、DDLがメタデータを取るタイミングで他のトランザクションがそのテーブルのレコードをreadしてcommitもrollbackもせずにいたりすると、DDLの後ろのトランザクションはshared lockも取れないのでそのテーブルに読み取りも書き込みもできなくなってしまいます。
今回の”Table definition has changed”はどういうケースで起きるかというと、テーブル定義が変更されるより先にトランザクションが開始されているが、テーブル定義の変更後にそのトランザクションがテーブル定義変更対象のテーブルにアクセスする場合に起こるという感じです。もしテーブル定義変更前に対象のテーブルにアクセスがあった場合はメタデータロックを先にそのトランザクションが取っているのでこのエラーは出ないはずです。また、テーブル定義変更後のトランザクションは問題なくテーブルにアクセスができます。
なので、このエラーがDDL実行から少し経ってから発生しても、タイミング的にDDLを跨いでるトランザクションのみが対象なのでエラーは一部のトランザクションに絞られると言えます。ただ、そんな長時間のトランザクションがあると、トランザクションのクエリの実行順序が違えばメタデータロック待ちになったと思うので運がよかったと考えるのがいいのかなと思いました。
「テーブル定義が変更される」とは
先ほどなんとなく出した「テーブル定義が変更される」という言葉ですが、ALGORITHM=INSTANTの場合はDDLが一瞬で終わるのでDDLの実行とほぼ同じ意味と考えてよさそうですが、ALGORITHM=COPYの場合は新しいテーブル定義でデータをコピーして最後にコピー先を新しいテーブルとする感じの挙動なので長時間かかる事もあり、いつの事かが気になります。
これは最初に引用したドキュメントからも察する事ができますが、コピーが完了して最後にコピー先を新しいテーブルとするタイミングのようです。ALGORITHM=COPYの時に最後のテーブルを切り替える直前でsleepを入れたり*2して確認しました。(大きいテーブル用意して試す方が確実ですが...)
余談ですが「テーブル定義が変更される」タイミングでメタデータロックを取るのでメタデータロック待ちが発生したり、それ対策でDDLのセッションでlock_wait_timeoutを短く取ってるとここでDDLが失敗してがんばったコピーが無駄になったりする事もあるようです。*3
トランザクション分離レベルによる挙動の違い
このエラーはconsisten readができなくなる事に起因するエラーなのでtx_isolation=”READ-COMMITTED”なら問題が起きない事が期待できます。実際最初のサンプルでsession1でSET TRANSACTION ISOLATION LEVEL READ-COMMITTED;を先にしてから実行するとエラーは発生しませんでした。これはREAD-COMMITTEDなのでDDLがcommitされてたら新しいバージョンを読めば問題ないという事ですね。
最後に
以上です。REPEATABLE READで使うならロングトランザクションを避けましょう、みたいな結論にしかならないかもですが勉強になりました。
データ変更を伴うバッチ処理を書く時に考慮していること
こんにちは、![]() id:shallow1729です。最近はインフラ寄りなお仕事をよくやっていますがこれまでにいくつかデータ移行やデータ基盤構築などのバッチ処理のお仕事をしてきました。以前にも一度そういった経験を元に記事を書いたのですが、MySQLやシステムに関する知識が以前よりも増えた今もう一度書き直したいなと思いました。
id:shallow1729です。最近はインフラ寄りなお仕事をよくやっていますがこれまでにいくつかデータ移行やデータ基盤構築などのバッチ処理のお仕事をしてきました。以前にも一度そういった経験を元に記事を書いたのですが、MySQLやシステムに関する知識が以前よりも増えた今もう一度書き直したいなと思いました。
なので今回はバッチ処理を書く時のテクニック2022版という感じです。今の仕事の関係でMySQLやrailsを前提にしている話が多いですが、おそらく他のデータベースを使っている人にも役に立つ話が多いのではないかと思います。ただ、今回の記事は経験に基づくものが多く、あまりよくないアイデアもあるかもしれません。改善点や間違いなどあればご指摘ください。
冪等性を持つように
冪等性とは端的に言えばある操作を複数回実行しても一回しか実行しなかった時と同じ結果になる性質の事です。長時間かかるバッチはしばしば途中で失敗します。事前の試運転で気づけるバグもありますが、デッドロックやロック待ちのタイムアウトのような並列実行の影響やネットワークタイムアウト、サーバーのOOM kill、外部apiのrate limitなど実際に動かしてみて初めて気づく事もよくあると思います。なのでこけたらもう一回実行できるように作る事が重要です。
冪等性を壊すやつらとしては例えば以下のような奴らがいます。
- auto increment
- uuidやulidなどのランダムな値
- タイムスタンプ
もちろん全てのデータが冪等である必要は無いと思います。例えば更新のタイムスタンプとかは都度最新のものになって欲しい事があると思います。
ただ、例えばあるテーブルのレコードの内容を別のテーブルにコピーする時にコピー先のidを新規に払い出したりすると元のテーブルでどこまでコピーされたかを把握するのは難しくなります。なので基本的にはなるべく先ほど述べたような冪等性を壊すようなやつらは新規に払い出さない方がいいです。
とはいえ。例えば水平シャードされていてidがグローバルにユニークじゃないケースでそれらをマージしたものを作ろうとするとこういった問題は避けられません。そういったケースでうまくやる作戦の一つとして「これらの値を払い出すフェーズとバッチ処理のフェーズを分割しておく」という手はあると思います。例えばあるテーブルのデータを別のテーブルにコピーする時はコピー元とコピー先のidのマッピングを先に作って永続化しておけば、再実行するときにinsert済の箇所はすでにレコードが入っている事が分かります。こうなっていればupsertにすれば冪等にできるかなと思います。
途中からの再実行をできるように
短時間のスクリプトであれば冪等性を担保できれば十分ですが、数時間かかる処理の場合は冪等性に加えて途中からの再実行も欲しい機能です。丸一日かけて90%まで進んだところで失敗して1からやり直しはつらい事が多いと思います。また、「普段は大丈夫だったけどある日突然大量のインプットが来て何回再実行してもタイムアウトで死ぬ」という事はあるので大事なバッチ処理は先んじて再実行できるようにしておけると良いと思います。
途中からの再実行を行うためには「処理をこまめにセーブする事」と「まだ処理がされていない箇所を把握できる事」が特に大事だと思います。「処理をこまめにセーブする」にはDBへのリクエストならトランザクションを細かく分割した上で、何かしらの形で「ここまでは処理を終えた」と分かるようにする必要があります。重要なのは「ここまでは終えた」と分かるように処理を作る必要があるという事で、データ更新ならid何番までは処理した、とか何時より前のデータは処理したと分かるように作る必要があるという感じです。
「途中から再実行」の技術はページネーションで調べるとオフセット法やシーク法というのが出てくると思います。MySQL的には一般にシーク法の方が嬉しいですがオフセット法の方が書きやすい印象なので無理に最初から最適化しなくていいと思います。
あわせてですが、途中からの再実行を実現するためには「途中の状態が許容される事」も重要です。稼働中のサービスの場合に一部のデータは更新済み、他は未更新という状態が許容されるようにバッチ以外含めて設計しておけると良いと思います。
ユーザー影響の削減
稼働中のサービスの裏でバッチが動く時はユーザー影響をなるべく小さくなるように作った方が良いです。
トランザクションはなるべく短く
トランザクションはなるべくすぐに抜けるようにした方が良いです。長いトランザクションはシステム全体のパフォーマンスを悪くしますし、この後説明するギャップロックのように想定外にユーザー影響を与えるロックを取ってしまうリスクがあるのでリスクヘッジの意味でもトランザクションを短くした方が良いです。トランザクションを開始する前にできる事をなるべくやってから開始、最低限の処理をやってトランザクションをコミットするのが大切です。
また、ユーザーもアクセスするようなテーブルについて大量のデータを一度に更新するのは避けて、ほとほどのサイズに分けて更新すると良いです。細かすぎるとN+1問題の弊害が大きくなるのでほどほどが大事です。 バッチスクリプトのパフォーマンスを確認する時はトランザクションの開始から終了までの時間を計ると良いです。この時間がユーザーがそのデータの書き込みできない時間になります。その時間がサービス的に許容できるか考えるのが大事です。
ロックをとる範囲はなるべく少なく
「トランザクションはなるべく短く」に近いですが、ロックを取る範囲はなるべく少なくすると良いです。例えば今のデータを読んでその結果を元に何か更新するような場合は最初のread時にロックを取って、更新してから手放すのが基本ですが、データが変更される心配が無いケースであったり、データの正しさが結果整合で十分な場合などはread時にlockを取らないという戦略もあります。
MySQLの場合ロックを取る範囲を確認したい時はInnoDB Lock Monitorが便利です。これはinnodb_status_output_locksを有効にすると確認できます。例えばupdate … where cid=1;(cidはなんらかの外部キー)みたいなケースではこの検索に使うsecondary indexの検索中に操作したレコードのロックと後述するギャップロック、更新対象のレコードのprimary keyのレコードロックが確認できると思います(REPETABLE READの場合)。また、適切なsecondary indexがない場合使われるindex上で走査されたレコードが全てロックを取られると思います。
可能な限り削除/更新対象はユニークに定まるようにする
ロックについて特に見落としがちなのがMySQLでデフォルトのREPEATABLE READの場合に発生するギャップロックの影響です。例えばupdate … where cid=1;みたいなクエリを考えます。この時cidはnon uniqueな外部キーのカラムで、cidのインデックスが貼られているとします。このクエリが実行中ロックを取る範囲は手元で試したところ「cidのindexのcid=1のレコードロック」、「cidのindexのcid=1の値が入る場所(新規にcid=1のレコードがinsertされる場所)のギャップロック」、「primary keyのcid=1のレコードロック」でした。MySQLはREPETABLE READの場合実行中にクエリの実行対象が増える事を防ぐためにクエリの実行中はcid=1のレコードのinsertをさせないようにしています。これは例えばlockを取らずにselectで更新対象のprimary keyを取得して、取得したprimary keyで指定して更新すれば「primary keyのcid=1のレコード」だけをロックの対象にする事ができます。ただし、これはselectしてから更新するまでに新規に作られたcid=1のレコードは更新できない事に注意してください。
今回はupdateを例にしましたが、これらの現象はdeleteでも起きます。deleteの場合は特に空振りするとネクストキーロックと言って空振りした前後の空の範囲にもロックを取るため大きな影響がでるリスクがあります。いずれにしてもunique keyで対象をuniqueになるように絞れば問題の影響範囲は最小限に抑えられると思います。
単一プロセスのパフォーマンス向上
パフォーマンスについて考える時は計測するのが大事です。バッチ処理は実行環境を用意するのが難しいケースが多いので大変だと思いますが、さくっと何度でも試せるようにするのが大事です。片道切符のデータ変更のバッチなどの場合は都度データを戻すのが大変だと思うのでテストモードの時はトランザクションをロールバックするようにするとかは手だと思います。こういうのを実装しやすくする意味でもトランザクションの範囲を小さくするのは大切です。
バッチ処理の高速化で重要なのはN+1を防ぐ事です。rails5系の時はactiverecord-importなどが使われていましたがrails6だとinsert_allなど標準のメソッドでバッチ処理が行えます。
言ってる事はread系の画面を作る時の注意と同じ事なのですが、実際に経験しないと「書き込み系の処理だとディスクI/Oの方が問題でしょ?」みたいな感覚になるんじゃないかと思います。ですが実際前職での経験で書き込みのN+1の改善だけでデータ移行のバッチを60倍程度早くできたこともあるので結構大きな効果があると思います。
バッチ処理のN+1で特に難しいのが親子関係のあるようなデータのバッチです。よくやるのが親ごとでループを回して子だけバルクで処理するようなやつです。これだと親がN+1になります。親子ならいいですが孫まで出てくるとナイーブな作りでは高速化できません。
こういうケースの戦略はORMの構造体(ActiveRecordのモデルなど)にインメモリにまずinsert/updateしたいデータを構築して、最後にまとめてバルクで処理するというものです。このやり方なら元のロジックを崩さず、可読性を保った形で全体をバルクで処理する事ができます。
並列実行によるパフォーマンス向上
メンテ中など負荷は気にしなくていいけど短時間で終わらせないといけない時は並列実行できるように設計すると良いです。並列化の戦略は「ユーザー影響の削減」のところと似たような感じです。他のプロセスがユーザーのプロセスかバッチのプロセスかという違いです。
各バッチについて担当範囲がかぶらないように注意して、処理の途中でもギャップロックなどによるロック競合が起きないように気を遣ったロジックにする事が大事です。
負荷対策
N+1を防ぐ、処理の分割、トランザクションを短く、などをきちんと行えば自然と負荷対策になると思っているのでここについては追加で書く事があまりないのですが、定期的にsleepを入れるのはよくやると思います。注意点として初歩的な事ですがsleepのタイミングは必ずトランザクションの外にした方が良いです。トランザクションを手放す前にsleepするとロックがかかったままになるので。
負荷も「試してから考える」でいいと思います。あとは、止めていい処理なら想定外に負荷が上がったら止められるように作るのが大事だと思います。それは冪等に作るとか途中から再実行できるようにするというのと同じような事だと思います。
バッチサイズの制御
負荷のコントロールの難しい内容としてはバッチサイズの制御の話があります。例えば親、子、孫のテーブルのデータを処理して他のテーブルにコピーするような時に親テーブルでバッチサイズを決めてループを回すのがよくやる方法ですが、親のバッチサイズが100としてもバッチ毎に子が1000、孫が10000の事もあれば子も孫も100の事もあります。このようにバッチサイズは親テーブルだけでは十分にコントロールできないケースもあります。こういう時の戦略として前職でやったのは、先に子や孫のidだけ先読みして一定サイズに分割してコピー先のidとのマッピングを永続化(冪等性のところで解説したような手法です)して、親をコピーするフェーズ、子をコピーするフェーズ、孫をコピーするフェーズに分けてそれぞれでバッチサイズを決めてコピーするという事をやりました。外部キーにつっこみたいデータも先に払い出されているのでテーブル毎でのコピーが可能になります。ただ、この作戦はメンテ中などユーザーによってデータが触られないケースでないと難しいと思います。
データ同期で気をつけたいデータ不整合
バッチ処理でよくやるのがあるDBやテーブルのデータに何らかの処理をして別のDBやテーブルにコピーをするというやつです。世間的にニーズが多いのでツールは多い一方で基本的に難しいのでどういうところが難しいかについて書きました。
何が難しいかと言うとソースのデータの変更、削除を追跡するのが難しいからです。 まず単純なappend onlyなログの場合のようにdeleteやupdateが発生しないデータの同期を考えます。この場合データ同期はもし途中でこけてしまってもコピー先の最後のレコードのidやタイムスタンプを見て、それより大きい値のレコードを再同期すれば十分です。
問題はdeleteやupdateが発生した時です。前回のコピーの後に更新された箇所は更新のタイムスタンプがあれば追跡できるかもしれませんが、そのタイムスタンプの更新漏れのリスクはあると思いますし、deleteされた箇所を得るのは困難です。
updateやdeleteの問題を避けるシンプルな戦略としては以下のようなケースが思いつきます。
- 更新を止めて同期する
- ワンタイムであれば同期中にupdateやdeleteが走らないようにすればこの問題は解決できます。
- ログの形式にする
- 先ほどappend onlyならコピーが簡単と書いたのですが、updateやdeleteもappend onlyなログの形式に変換するというイメージです。*1
- 毎回全部コピー
- 全データを毎回全部入れ替えたらdeleteやupdateもちゃんと反映されます。BigQueryみたいなむっちゃ安いストレージに対してならありな戦略だと思います。
- 削除しない
- updateだけならタイムスタンプを信用して前回の処理以降のタイムスタンプを使えば良いのでまだ実現が可能です。この場合削除は論理削除というものになります。ただ、僕はdeleted_atを用いた論理削除でつらい経験(意図せず削除したはずのデータがユーザーに見えるなど)をした事があり、開発上のデメリットが大きいと感じています。削除済みレコードテーブルを別で用意するとかだとまだ安心できるかもしれないですが僕は経験が無いです。
もしこういった単純な方法が困難な場合はpt-online-schema-changeが行っているようにdatabaseのトリガーを用いる方法やAWS Database Migration Serviceなどがおそらく内部的にやっているバイナリログを用いた方法などで更新を追跡する必要があると思います。
最後に
自分がぱっと思いつく範囲でバッチ処理のテクニックをまとめました。何か参考になることがあれば嬉しいです。
*1:追記: 例えばレコードの更新時にログテーブルに更新内容を一緒に書いて、定期的にそのログテーブルの内容を元に同期する、とかです。ログテーブルに書き込む時点で最初の方に書いた冪等性を崩すようなデータを払い出して保存しておけば冪等にデータを同期できるかなと。
pt-online-schema-changeによる負荷を好きなメトリクスでコントロールする
こんにちは、![]() id:shallow1729です。この記事はMySQL Advent Calendar 202119日目のものです。昨日は
id:shallow1729です。この記事はMySQL Advent Calendar 202119日目のものです。昨日は![]() id:next4us-tiさんでMySQL8.0を再起動するとアプリからつながらなくなる理由でした。インターネットって情報はたくさんあるけど分かってないと検索できないケースが多いと思っていて、ユーザーの立場に立って記事を書いているというのが伝わってすごくいいなと思いました。僕も会社のMySQlを8系にする時のトラブルシューティングをうまくやるために参考にしようと思います。
id:next4us-tiさんでMySQL8.0を再起動するとアプリからつながらなくなる理由でした。インターネットって情報はたくさんあるけど分かってないと検索できないケースが多いと思っていて、ユーザーの立場に立って記事を書いているというのが伝わってすごくいいなと思いました。僕も会社のMySQlを8系にする時のトラブルシューティングをうまくやるために参考にしようと思います。
今回はpt-online-schema-changeを自分向けに改造した話です。
pt-online-schema-change(pt-osc)
pt-oscはカラムのデータ型の変更のようなオンラインDDLが使えないalter tableをオンラインで行いたいケースなどに使えるツールです。このMySQL advent calenderでもpt-online-schema-changeとgh-ostの比較(データが損失するかもしれないAlterTable編)で![]() id:kenken0807さんが話題にしているようにデータベース屋さんの間だと結構有名なツールだと思います。
id:kenken0807さんが話題にしているようにデータベース屋さんの間だと結構有名なツールだと思います。
pt-osc自体の解説は特にしませんが基本的な挙動としては以下のイメージです。
- alter table後のテーブル定義の新しいテーブルを作成
- 元のテーブルのレコードを新しいテーブルにコピー、この間に起きる元のテーブルへのinsertやupdateはtriggerで拾う
- 新しいテーブルの名前をコピー元のテーブル名にrenameする事で新しいテーブル定義への変更を完了する
alter table済みのコピーを作成してrenameで入れ替えるという感じですね。
pt-oscの負荷の制御の仕組みの改造
先ほどの動作の説明で出たレコードのコピーについては当然負荷がかかるのでpt-oscは--max-loadというオプションでMySQLの状態を見て負荷が高そうならコピーを止めるという事をやってくれるのですが、SHOW GLOBAL STATUSで取得できるものしかサポートされておらず、インスタンスのCPU使用率のような負荷状況の監視に用いるようなメトリクスでの制御はできませんでした。実際pt-oscのデフォルトはThreads_running(sleepでないスレッド数)を見ながらコピーの頻度を制御するのですが、アクセスのほとんどない検証環境で動かしてみるとCPU使用率が100%に張り付いてしまいました。まあ本番ならいっぱいアクセスあるだろうし大丈夫かな?と思いつつも制御できるなら制御したいと思って制御できるようにコードを変更したものが以下です。
$varが--max-loadで渡した値のメトリクス名のようなので、この値で分岐して独自のメトリクス取得方法を実装した感じです。僕のサンプルだとcpuutilizationというのを--max-loadで指定できるようにして、AWSのcloudwatch metricsで取得したRDSのCPU使用率が指定した値を上回るとコピーを止める事ができるようにしています。
一応実際に軽く動かしてみてCPU使用率が--max-loadで渡した値を下回るまではコピーが進まない事の確認はしましたが、本番での活用は自己責任でお願いします。
$ DB_INSTANCE=database-1 pt-online-schema-change --alter "add column c1 int" D=test,t=sample --password testtest --user root --host localhost --execute --max-load cpuutilization=7 --chunk-size 10 No slaves found. See --recursion-method if host ip-172-31-37-79.ap-northeast-1.compute.internal has slaves. Not checking slave lag because no slaves were found and --check-slave-lag was not specified. cpu utilization is 7.33333333333334 Operation, tries, wait: analyze_table, 10, 1 copy_rows, 10, 0.25 create_triggers, 10, 1 drop_triggers, 10, 1 swap_tables, 10, 1 update_foreign_keys, 10, 1 Altering `test`.`sample`... Creating new table... Created new table test.____sample_new OK. Altering new table... Altered `test`.`____sample_new` OK. 2021-12-16T10:46:28 Creating triggers... 2021-12-16T10:46:28 Created triggers OK. 2021-12-16T10:46:28 Copying approximately 15 rows... cpu utilization is 7.33333333333334 Pausing because cpuutilization=7.33333333333334. cpu utilization is 7.33333333333334 ... cpu utilization is 7.33333333333334 Pausing because cpuutilization=7.33333333333334. cpu utilization is 7.33333333333334 cpu utilization is 6.39344262295083 2021-12-16T10:48:01 Copied rows OK. 2021-12-16T10:48:01 Analyzing new table... 2021-12-16T10:48:01 Swapping tables... 2021-12-16T10:48:01 Swapped original and new tables OK. 2021-12-16T10:48:01 Dropping old table... 2021-12-16T10:48:02 Dropped old table `test`.`_sample_old` OK. 2021-12-16T10:48:02 Dropping triggers... 2021-12-16T10:48:02 Dropped triggers OK. Successfully altered `test`.`sample`.
最後に
以上です。percona toolkitはGPL2.0で、コードを変更して公開する分には問題ないはずだと思っていますが何か問題あれば教えてください。
明日はyy_hrachiさんです!おたのしみに〜
InnoDBのMVCCのガベージコレクションについて
こんにちは、shallow1729:detailです。今回は先日MyNA会というイベントで発表したMySQLの標準のストレージエンジンであるInnoDBのMVCCのガベージコレクションについて書こうと思います。発表自体もアーカイブされているので以下から見る事ができます。
「日本MySQLユーザ会会(MyNA会) 2021年07月 -下位レイヤ勉強会-」 公開版 - YouTube
まず前半ではMVCCに関連するデータ構造を見ながらガベージコレクションの重要性やlong-running transactionの問題点について解説します。後半では実際のガベージコレクション(purge)の処理をソースコードレベルで追いながら、ユーザーに提供されているパラメーターを解説をします。
これまでに比べると踏み込んだ話題なのであまり基礎的な事は解説しません。知らない単語が多いかもしれないですが、適宜調べながら読んでいただけたらと思います。また、ユーザー視点でも面白い話題になるように工夫はしたつもりですが、ユーザー向けに伝えたいメッセージは「long-running transactionは避けよう」だけです。どちらかというと実際のデータ構造やソースコードを紹介して、読んでくださった方にデータベース面白いなって思って欲しいという気持ちです。
以下の解説ではMySQL5.7.32をベースに解説します。
MVCCについて
MVCCは複数のトランザクションが同時にデータベースにアクセスした際に、それらのトランザクションをうまく分離して捌くための仕組み(ACID特性のIの実装方法の一つ)です。MVCC以外の同時実行制御の実装方法としてはTwo-phase lockingやTimestamp Ordering Protocolなどがあるのですが、MVCCの特徴は他のトランザクションの書き込みが読み取りをブロックせず、他のトランザクションの読み取りも書き込みをブロックしないという性質です。そのためパフォーマンスが良いのでInnoDBなど多くのデータベースで使用されています。
InnoDBのMVCCのイメージはトランザクションの開始時にその瞬間のデータベースの状態のスナップショットを撮り、その上でデータの読み取りを行うイメージです。図に示すように複数のトランザクションが同時に開始した際、それぞれがデータベースの状態のスナップショットを撮るのでお互いのトランザクションの読み書きは独立して行えます。

ちなみにMySQLのデフォルトのトランザクション分離レベルはREPEATABLE READで、SERIALIZABLE(トランザクションが同時に一つしか動いていないのに対応する分離レベル)ではないのでlost updateなどいくつかのanomaly(複数のトランザクションが同時に実行される事で起きる変な事)を防ぐ事はできません。なのでSELECT FOR UPDATEなどでユーザーが明示的にロックを取得する必要があります。
MVCCでできるゴミ
MVCCはトランザクション間でのブロックが発生しにくいのでパフォーマンスが良いのですが、一方でデータを共有していた場合に比べるとトランザクション毎のスナップショットを保持するための追加のデータ領域が必要になります。なので、あらゆるタイミング(バージョン)のスナップショットにアクセスするには過去のスナップショットを全て保持する必要があります。ですが実際にはトランザクション開始時のスナップショットが使われるので古いバージョンのスナップショットは、そのスナップショットを見ているトランザクションが完了(commit or rollback)すれば誰もアクセスできなくなるので捨てる事ができます。
あとで詳しく見ていくように、スナップショットをいつまでも放置しているとデータ容量的にもパフォーマンス的にもよくないのでガベージコレクション(InnoDB的にはpurge)する必要があります。
スナップショットを作るために必要なデータ構造
ガベージコレクションを理解するためにはまずInnoDBがスナップショットをどう表現しているかを考える必要があります。先ほどまではあたかもトランザクション開始時にデータを全てdeep copyするかのような表現をしましたが、実際は差分のみを保存する形で実現します。
まず、スナップショットを考えない場合にInnoDBがデータをどう保存、アクセスしているかを見ていきましょう。

ここにInnoDBで使っているスナップショットの情報を追加すると以下のようになります。

また、各トランザクションがどのバージョンのデータを見ればよいか(visibility)を確認するためにclustered indexのレコードやundo logにはタイムスタンプ(TRX_ID)があります。
B+ Treeの葉ノードに削除マークが必要なのは、たとえあるトランザクションに削除されたレコードでも別のトランザクションからはまだ見えるものかもしれないからです。削除マークがついたレコードは全てのトランザクションから見えなくなった時にpurgeの対象にできます。
undo logは更新が行われる度に伸びていく差分ログですが、こちらもいずれ古い差分は誰も見なくなるのでpurgeの対象にできます。
undo logの保存方法
ここからは先ほど説明した各データ構造についてより詳細に見ていこうと思います。まずはundo logについて、どのように保存されているかを見ていきます。

undo logはrollback segmentという領域にundo log recordとしてためられます。この領域はバッファープール上にもありますし、crash recoveryでもundoは必要なのでストレージにも割り当てられています。
rollback segmentはトランザクション毎に割り当てられて、そのトランザクションが更新を行なった場合、古いバージョンへの差分(undo log record)がrollback segmentに書き込まれます。なので、rollback segmentのundo log recordを使えば、そのrollback segmentに割り当てられたトランザクションの開始前のバージョンを見る事ができます。
clustered indexのレコードは最新のundo logへのポインターを保持しており、undo log recordは一つ前のundo log recordへのポインターを持つという形になっているので、過去のバージョンが欲しい時はポインターをたどる事で実現します。
undo logをpurgeできるタイミング
最初の方で原理的にはスナップショットはそれを見ているトランザクションが不要になったら捨てられると述べましたが、実際はもう少しナイーブな方法でpurgeの対象を決めています。
先ほどのundo logの保存方法からその更新を行なったトランザクションとundo log recordが紐づいている事がわかります。undo log recordはその更新を行ったトランザクション以前のバージョンにアクセスするために使うものなので、もしその更新を行ったトランザクションのcommit以後のトランザクションしかアクティブで無ければ、そのundo log recordはpurgeできる事になります。なのでInnoDBはこの発想でpurge対象を決めています。
一方この判断方法で全てのゴミを捨てられるわけではありません。アクティブなトランザクションの後に始まったトランザクションがレコードを二度更新した場合、誰からも見えなくなるバージョンが発生し得ますがこのゴミは捨てる事ができません。
undo logをpurgeするためのデータ構造 history_list
先ほどの解説でundo logのpurge基準はその変更をしたトランザクションのコミットより後のトランザクションしかいなくなった時という事が分かりました。なのでうまくコミットした順序になるようにundo log recordをlinked listなどで繋げておくとその順番を辿ってpurgeを行える事が分かります。InnoDBではこのデータ構造をhistory_listと呼びます。
history_listはトランザクションのコミット時にそのトランザクションのundo log recordを末尾に繋げていく事でcommit順になるようにしています。後で述べるようにlong-running transactionはシステム全体のパフォーマンスへの悪影響を及ぼすのでそれを監視するためにhistory_list_lengthを監視する事があると思いますが、history_list_lengthというのはこのcommitされたpurge前のhistory_listの長さの事です。undo log recordの数という意味だと未コミットのトランザクションのundo log recordもあるので少しずれます。
また、InnoDBはhistory_listとほぼ同じ情報を持つデータ構造としてpurge_queueというデータ構造も持っています。これはトランザクションのcommit時に払い出されるtrx_noというインクリメンタルなIDの順序に並ぶようにrollback segmentへのポインターを保持するpriority queueで、後で見るpurge処理のパフォーマンス向上の目的で使っているようです。linked listとpriority queueなのでデータ構造は違いますがhistory_listはcritical sectionで伸ばされて、trx_noも同一のcritical sectionで払い出されるので中身は同じものと考えて大丈夫です。

レコードの削除時のclustered index
undo logの解説だけでかなりの量になってしまったのですが、先ほど述べたようにスナップショットの保持には削除マークがついた葉ノードも発生します。
clustered indexの葉ノードは削除された場合その削除を行ったTRX_IDと削除マークを持っています。削除マークのついた葉ノードはundo logのpurgeのタイミングでそのrollback segmentのTRX_IDと同じTRX_IDによる削除がされた葉ノードを物理的に削除します。*1

レコードの更新時のsecondary index
clustered indexについては一般的にprimary keyが更新される事を考える必要がないと思いますが、secondary indexについてはレコード更新によってindexに用いているカラムが更新される可能性について考える必要があります。例えばintegerのカラムの順序で並ぶsecondary indexの場合、そのカラムの値が10から20になると、10だった葉ノードは11や12を追い越すので別の場所に移動する可能性があります。この更新のコミット前に始まった別のトランザクションが1~15の範囲で検索していると、単に葉ノードの位置を変えてしまうとそのトランザクションだと本来見えていたはずの葉ノードが見えなくなります。なのでこれを防ぐためにsecondary indexに関連するカラムの更新時は古い葉ノードに削除マークをつけて新しい葉ノードをinsertする形で複数のバージョンのスナップショットを提供しています。削除マークのついた葉ノードのpurgeはclustered indexの方で解説したようにundo logのpurgeの中で行います。

secondary indexのvisibilityとcovering index
これまでの解説から考えられるsecondary indexで検索した時の挙動は、削除マークがついている葉ノードの時はその葉ノードのTRX_IDを見て自分が見て良いかを判断するというものですが、実はsecondary indexの葉ノードはTRX_IDを持ちません。
ではどうやってvisibilityを判断するかというと、covering indexが効かないレコードを取得する時と同じように、TRX_IDを持つclustered indexを見にいく形で判断しています。
そのため、削除マークがついた葉ノードについてはたとえ自分からは見えないバージョンの葉ノードだったとしても飛ばす事はできず、必ずclustered indexを見に行きます。また、clustered indexを見にいかないといけないのでcovering indexも効かなくなります。結果として削除マークのついた葉ノードを放置しているとシステム全体のパフォーマンスがどんどん悪くなっていきます。これがガベージコレクションの必要な理由の一つです。
long-running transactionの問題点の考察
MySQLのバッドプラクティスの一つとして長時間コミットされないトランザクション(long-running transaction)があります。ここまでの解説からlong-running transactionがなぜ問題かを考えていきます。
まず、long-running transactionが存在する場合、そのトランザクション以後に作られたスナップショットのゴミは捨てる事ができません。また、secondary indexの検索でみたように、ゴミがたまるほどパフォーマンスが悪くなってしまいます。そのため、long-running transactionの存在はpurgeを阻害するためにシステム全体のパフォーマンスを悪化させてしまいます。
ここで重要なのはlong-running transactionがどのテーブルを見るかをデータベースは知らないという事です。そのため、long-running transactionがたとえ一部のテーブルにしか関心を持っていなかったとしてもシステム全体のパフォーマンスはどんどん悪くなっていきます。また、long-running transaction自身については遡るundo logがどんどん増えるのでパフォーマンスはさらに悪化していきます。以上の理由から、long-running transactionはバッドプラクティスと考えられます。
purgeのパフォーマンスに関わるパラメーター
ここまででpurge対象となるデータやpurgeのタイミングについて解説しました。次にpurge処理の大まかな流れを書こうと思うのですが、今回はユーザーが設定できるパラメーターの理解に繋がるようなまとめ方をしようと思っているので、先に注目したいパラメーターをまとめます。
innodb_max_purge_lag
innodb_max_purge_lagの値がhistory_listの長さが閾値を越えるとDMLにsleepを挟むというものです。これによって書き込みにpurgeが追いつかないような時に無理やりpurgeを間に合わせる事ができます。
innodb_purge_batch_size
これは後で解説するpurge処理の一サイクルで処理するundo logの数です。これを設定する事で一サイクルあたりに処理するundo logの数や128回に1回行われるrollback segmentからundo logをtruncateする量をコントロールできます。
innodb_purge_threads
purge処理に割り当てるthreadの数です。
以下ではこれらのパラメーターに注目しながらpurge処理を見ていこうと思います。
purge処理の流れ
まず、図で示すものがpurge処理の全体像です。以下で一つ一つのステップについて解説します。

purgeのメインスレッド
まず、InnoDBはpurge処理をpurge_coordinator_threadというバックグラウンドスレッドが行います。このスレッドはpurgeに関わるメインスレッドで、シングルスレッドで動いています。
purgeの遅れ度合いの計算
purge_coordinator_threadはまずtrx_purge_dml_delayというメソッドでhistory_listの長さをチェックします。もしhistory_listがinnodb_max_purge_lagより長かったらhistory_listとの差分からdmlの遅延時間を計算してsrv_dml_needed_delayというグローバルな変数に遅延時間を入れます。dml実行時はrow_mysql_delay_if_neededというところでsrv_dml_needed_delay分sleepを入れるようにしています。
purge対象のundo log recordの取得
次にtrx_purge_attach_undo_recsというメソッドでpurge対象のundo log recordをinnodb_purge_batch_size個取得します。これをどう行なっているかというと、undo logのpurgeのタイミングで解説したように現在アクティブなトランザクションより前にコミットしたトランザクションのundo logはpurgeできるので、まず現在アクティブな一番古いトランザクションを取得して、undo logがそのトランザクションより前に作られたかをチェックする事で実現しています。
「一番古いアクティブなトランザクションの取得」はclone_oldest_viewで行なっています。ここで取得されるReadViewという構造体はトランザクションのvisibilityを評価するために使う構造体で、トランザクション開始時までにコミットされたトランザクションやアクティブなトランザクションの情報を持っています。
purge対象のundo log recordの取得はtrx_purge_fetch_next_recで行います。この中を追ってみるとpuge_queue->popで新しいrollback segmentを取得しています。そして、このrollback segmentのundo log recordを取り出して、それを先ほど取得した一番古いアクティブなトランザクションと比較してpurgeして良いならpuge対象に追加する、という形で行なっています。
そして、innodb_purge_batch_size個取れるか、それ以上取れなくなったらこの処理を完了してpurge作業に入ります。
worker_threadへのジョブの依頼
purge作業では削除マークがついたB+ Treeの掃除やpurgeが完了したundo logにマークをつける処理が行われます。この処理はworker_threadにjob queueを介して依頼する形で行います。
worker_threadは広くInnoDBのバックグラウンドの処理を行うスレッドで、渡されたジョブのコンテキストに基づいていろいろやります。purgeに割り当てられるworker_threadの数はinnodb_purge_threads個です。そのため、innodb_purge_threadsはpurge処理を依頼できるworker_threadの数という事になります。
これらのworker_threadの処理が全て完了したらpurgeの一サイクルが完了します。
undo log recordのtruncate
サイクルが完了すると基本的には最初に戻るのですが、128回に一回rollback segmentのundo log recordのtruncateを行います。この処理によってrollback segmentを再利用可能な状態にします。
この処理はhistory_listを辿りながら行い、truncateが完了するとhistory_listからundo log recordが削除されるという仕組みです。truncateは毎回行う訳ではないのでpurge_queueとhistory_listという同じような情報を別々で用意した方がパフォーマンスがよくなります。
ちなみにundo logが溜まっている時にhistory_list_lengthを監視していると、この値が減らないフェーズが見える事があると思いますが、history_list_lengthが小さくなるのはこのtruncateのフェーズなので、worker_threadによるpurgeフェーズに時間がかかっているとhistory_listが減らない瞬間が見える現象が発生するというのが原因です。
ちなみになぜtruncateを別処理にしてるかについてですけど、work_queueが並列に動くとrollback segmentが再利用可能な状態になるかの判断がしんどいからかなーと思っています。
最後に
以上でInnoDBでのpurgeの解説になります。ニッチな話題と思われたかもですが、途中書いたようにMVCCのガベージコレクションはパフォーマンス的にも重要なものなので、OLAPとOLTPが混合するようなケースを想定したデータベースでは特に重要なもので、現在も研究が進められています。*2
長くなってしまいましたが、普段ブラックボックスとして使いがちなデータベースの中身について興味を持つきっかけになってもらえたらなーと思います。
*1:物理削除といってもoptimize tableを実行しない限りは再利用できるようにするだけです。
リンク集
データベース関連->database カテゴリーの記事一覧 - shallowな暮らし
プログラミングコンテスト関連->procon カテゴリーの記事一覧 - shallowな暮らし
雑多な開発テクニック-> development カテゴリーの記事一覧 - shallowな暮らし